

How fast is AI progress?
Top forecasters disagree

Welcome to The Update. Today’s post is an experiment. I give an overview of some of the most interesting contributions to a lively debate on AI progress. Quotations have been lightly polished for clarity.
On Thursday, METR’s Ajeya Cotra wrote that she had ‘underestimated AI capabilities again’:
For the first time, I don’t see solid evidence against AI R&D automation *this year.*
Naturally, this got quite a lot of attention. If AI could be used to create its own successor, progress would be accelerated. (Though note that Ajeya’s estimate is lower than it might seem: she later clarified that she thinks the chance of AI R&D automation in 2026 is ten percent.)
Superforecaster Peter Wildeford weighed in:
I think I’d forecast:
~2026-2030 -- AI replaces ~all AI researchers
~2027-2033 -- AI replaces ~all white collar industry
~2032-2040 -- AI replaces ~all human industry
~2033-2042 -- All humans dead or obsolete
Eli Lifland, one of the authors of the AI Futures Model (the successor to AI 2027), responded:
Do you have a sense of the crux of why your takeoff is so much slower than https://aifuturesmodel.com?
(Eli’s median estimate is that it will take around two years – depending on how you interpret key terms – from Peter’s first step to his last.)
Does your model account for bottlenecks in diffusion?
That is, does it allow for the fact that it may take time for individuals and companies to adopt new AI systems?
Eli:
Not in a very smart way. We mostly focus on AI R&D capabilities. I don’t think those particular bottlenecks are very large though.
. . .
At a high level, I think superintelligence will be so capable that there will be extreme costs to not adopting it quickly. And thus there will be race dynamics, even if people don’t adopt it readily in the first place.
It’s striking that Eli and Peter take such different views on this, since both expect AI progress to be fast and both are top forecasters.
The benchmark-reality gap
Ajeya’s update was motivated by surprisingly fast progress on METR’s time horizon metric for AI capabilities, which evaluates AI systems by how long the tasks they can complete would take a human expert. On 14th January, she estimated that by the end of the year, AI would be able to complete 24-hour software tasks at a 50 percent success rate. Seven weeks later, that figure had more than quadrupled, to over 100 hours. In Ajeya’s view, this means we may be drawing near to a crucial threshold. Once AI systems can reliably handle tasks lasting several weeks, she thinks they might be able to decompose longer tasks into smaller ones. This could allow them to complete arbitrarily long projects, opening the door to AI R&D automation.
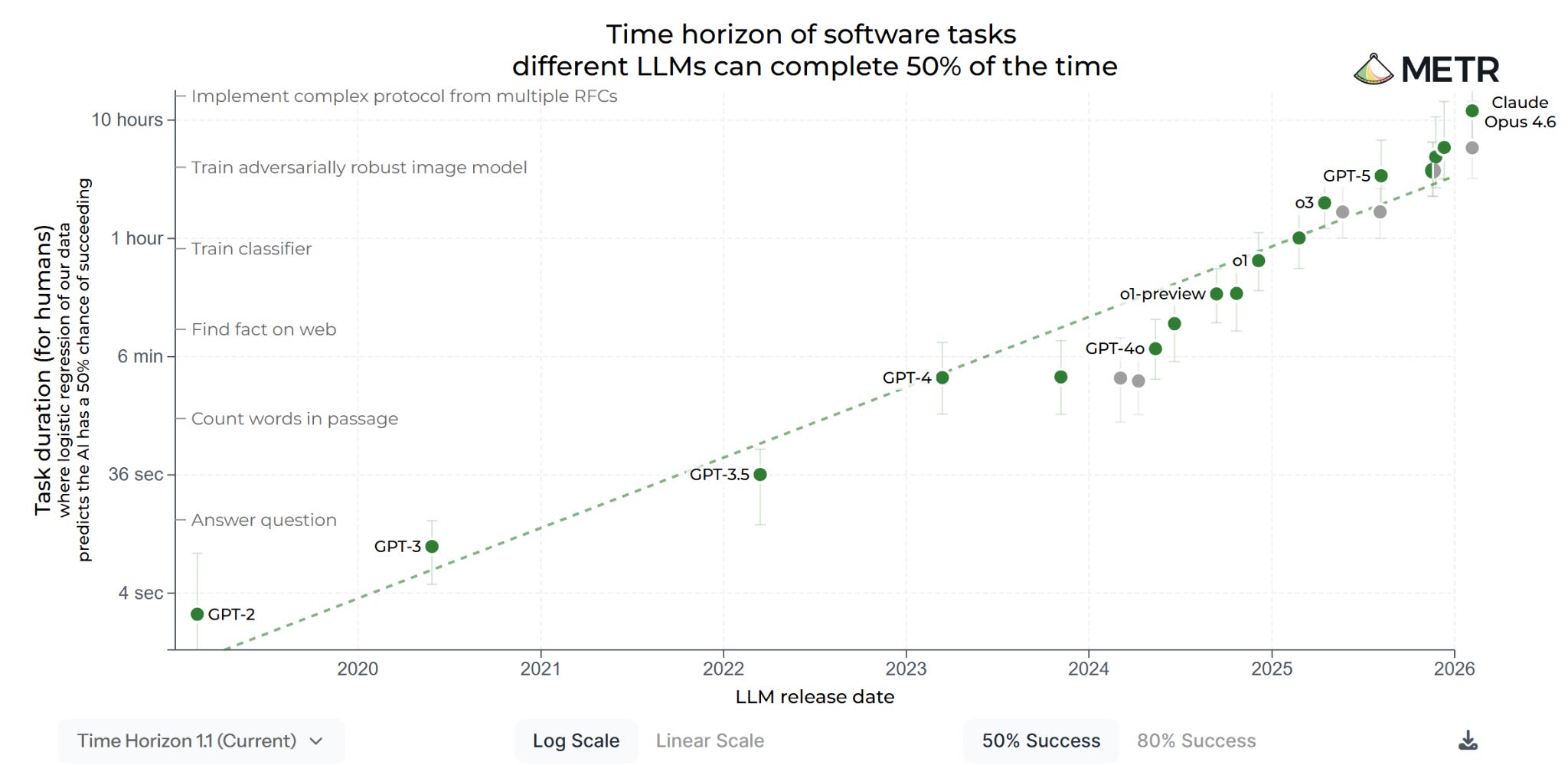
As I’ve discussed previously, METR’s time horizon metric plays a central role in the AI debate. But some are skeptical about how much it tells us. On Saturday, Matthew Barnett wrote:
I want to preregister that even once AIs can complete month-long tasks on the METR task suite (or rather, a future task suite capable of measuring at that scale), I don’t expect large, transformative effects on the world to quickly follow. There will be a benchmark-reality gap.
To make this claim more precise: within 3 years of AIs being capable of month-long tasks on the METR task suite, I don’t expect AIs to take over the world, elevate US economic growth by >10 percentage points, cause the US labor force participation rate to fall by >30%, or cause a billion people to die.
Why not? Because the METR task suite measures only a narrow slice of economically valuable tasks, mainly software tasks that can be easily graded. Even once AIs excel at these tasks, overall impact will be muted by numerous bottlenecks in the economy.
AIs capable of software engineering tasks won’t necessarily be good at management, long-term planning for fuzzy goals that lack clear criteria for success, or efficiently operating computers via mouse and graphical user interface interactions. I think all of these will be important bottlenecks.
I don’t anticipate wild, transformative effects on the economy, such as double-digit US GDP growth, until AIs are capable of general, highly reliable, open-ended autonomy on ambiguously defined goals. I don’t think the METR task suite currently measures this capability well.
Interestingly, many people agreed with Matthew and very few pushed back. The belief that METR’s tests are representative of real-world tasks may be rarer than it sometimes seems.
But what about automating AI R&D? Matthew thinks the benchmark-reality gap applies to that, too:
I expect strong performance on METR tasks translates into partial, not complete, automation of AI R&D. Moreover, I think even complete automation of AI R&D would probably only modestly accelerate AI progress, since progress would quickly become bottlenecked by compute and data.
Who should we trust?
Some of the forecasts in this debate can seem aggressive. In reaction to Peter Wildeford’s tweet, economist Itai Sher wrote:
Economist Jason Abaluck responded:
If someone with a demonstrably excellent forecasting record makes predictions that seem outlandish to you, the correct response is to update your beliefs, not mock them.
I have a lot of respect for Itai, but I agree with Jason. I don’t have very short AI timelines either, but the fact that some very smart and knowledgeable people do makes me worry that I may be wrong. We tend to trust our own judgments too much and should put more weight on the judgments of others.
That said, we should also be aware of a selection effect. If you believe that AI timelines are short, you’re more likely to find it important to develop relevant expertise. In this way, the pool of experts on AI timelines can become systematically skewed. Weighing all these considerations against one another is fiendishly difficult.
Good post! I propose to use the term "Schubertian sobriety" for this kind of level-headed analysis.
I think a large part of the gap in expectations is about generalization, or in different terms, how the correlations between the metrics and the capabilities degrade. Everyone agrees that the metrics are going to be overfit, and won't directly predict success - as you note - but if the correlation between measurable capabilities and hard to measure capabilities doesn't entirely disappear, we'll also see continued significant progress on the hard to measure items as well.
And evaluating the two theories performance to date, we have seen exactly the sort of general progress that broad generalization predicts - lower text prediction log-loss ended up leading to increased performance on a wide variety of tasks, and improved time horizon success aimed primarily at for software development has led to better writing, better qualitative analysis, and better mathematical capabilities. And this isn't back-forecasting, it's effectively exactly what those promoting the scaling hypothesis were betting on, and it has paid off in the last several generations of model.
Of course, it's always possible that the correlation between measured capability and most other tasks drops to zero, or even ends up perversely decreasing performance - but at that point, the generalization argument is that the developers will find (possibly harder to measure but at least temporarily) more robust measures to improve. Though, critically, this retargeting only works as long as we can observe the changes' impact on performance. And that's exactly the case that alignment researchers have been worried about for well over a decade, at this point.